Introduction
In September 2025, Anthropic unveiled Claude Sonnet 4.5, the latest evolution in its Claude model lineup. With bold claims of 30+ hours of autonomous work, stronger alignment, improved reasoning, and deep gains in coding prowess, this release marks a significant leap forward. In this post, we’ll dig into what makes Claude Sonnet 4.5 special, its key features and enhancements, potential use cases, comparisons with earlier versions, and considerations for adoption.
What Is Claude Sonnet 4.5?
Claude Sonnet 4.5 is the newest mid-tier model from Anthropic, designed to balance performance, cost, and agentic capability. It is positioned not as a bleeding-edge reasoning giant, but as a powerful, versatile workhorse for developers, teams, and AI agents.
Key facts:
- Anthropic claims it can operate autonomously over 30 hours on complex, multistep tasks—far beyond predecessors like Claude Opus 4, which lasted ~7 hours.
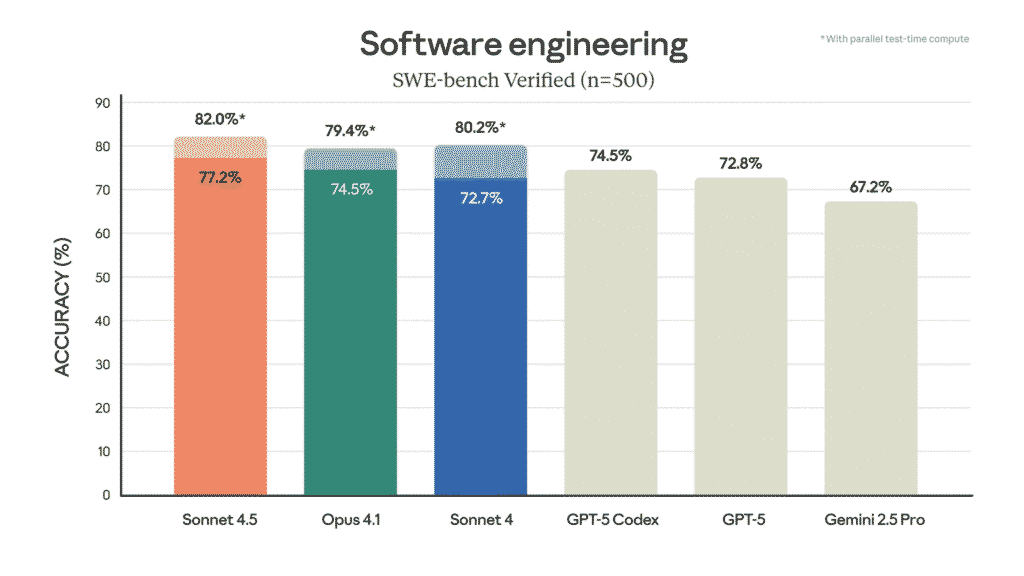
- It boasts state-of-the-art performance on coding benchmarks such as SWE-bench Verified.
- Other improvements include enhanced alignment (i.e. output consistency with safety/intent objectives), stronger reasoning/math capabilities, and refined “computer use” or autonomous tool-interaction behaviors.
- Along with the model release, Anthropic launched enhancements like a Claude Agent SDK, code checkpoints, context editing, and memory tools in their API.
Thus, Sonnet 4.5 is not just a bigger model—it’s intended to be more durable, dependable, and capable of sustaining long-horizon, real-world tasks.

Key Features & Improvements
Here are the standout features of Claude Sonnet 4.5:
1. Long-Horizon Autonomous Performance
The flagship claim is that it can sustain operation for over 30 hours on its own. That raises the bar for what “autonomous AI agents” might realistically handle. Earlier models struggled to maintain coherence or context over long durations; 4.5 is designed to overcome that.
2. Better Coding & Benchmark Results
Sonnet 4.5 tops coding benchmarks like SWE-bench Verified, demonstrating robust ability in end-to-end software tasks. Users mention that it feels “better for code” than competing models.
3. Improved Reasoning, Math & Knowledge
Along with coding, 4.5 delivers gains in reasoning, mathematical problem solving, and domain knowledge. Anthropic touts it as their most “aligned” model yet in terms of goal consistency.
4. Enhanced Agent Infrastructure
With the release, Anthropic also provided tools and infrastructure to make building agents easier:
- Claude Agent SDK: enabling developers to build custom agents leveraging 4.5.
- Code Checkpoints: Save & rollback states during long tasks.
- Context Editing & Memory Tools: help agents manage complexity and recall across steps.
5. Smarter Behavior & Clarification
In internal tests (e.g. in Augment Code), Sonnet 4.5 asked clarifying questions more often rather than making blind assumptions, reducing tool-call waste and missteps.
6. Drop-in Replacement & Compatibility
Anthropic positions 4.5 as a drop-in upgrade in many contexts (API, apps) without price changes, simplifying migration for existing users.

Use Cases & Scenarios
Claude Sonnet 4.5 is particularly suited for:
- Long-running software projects / agents: e.g. autonomous bug-fix, refactoring, or system orchestration over hours.
- Multistep workflows: where the model must retain memory, validate assumptions, check intermediate outputs.
- Complex coding tasks: building or refining large codebases, multiple modules, cross-file consistency.
- Autonomous agents: agents that monitor, adapt, and act over long durations (e.g. in finance, security, research).
- Hybrid workloads: combining reasoning, math, and domain knowledge (e.g. data analysis, research assistants).
For developers and organizations that require dependable, continuous AI operations without frequent resets, 4.5 is a compelling candidate.

| Characteristic | Prior Models (Sonnet 4 / Opus 4) | Claude Sonnet 4.5 |
|---|---|---|
| Sustained autonomy | ~7 hours (Opus 4) . | 30+ hours claim . |
| Benchmark coding | Strong (Opus often favored) . | State-of-the-art SWE-bench Verified . |
| Agent / tooling support | Moderate | Enhanced (Agent SDK, checkpoints, memory tools) |
| Clarification & behavior | More aggressive in completion | More cautious, asks clarifying queries |
| Alignment / safety | Strong baseline approach | Claimed “most aligned yet” |
Limitations & Considerations
While impressive, there are several caveats to keep in mind:
Availability / adoption lag
Full rollout to all users or platforms may take time; compatibility and stability could vary across environments.
Claims vs real-world constraints
The “30 hours” autonomous run is a claim under test conditions; real pipelines will expose edge cases, drift, or resource constraints.
Cost & resource demands
Running longer tasks or complex agents may consume more compute, memory, and infrastructure. Efficiency is critical.
Alignment tradeoffs
As models become more autonomous, the risk of goal misalignment or unexpected behaviors increases; rigorous guardrails remain necessary.
Domain specificity
In highly specialized domains (e.g. advanced scientific research, niche legal reasoning) further fine-tuning or hybrid architectures may still outperform a general model.